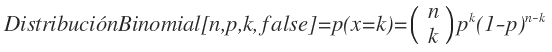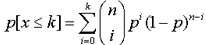|
Una de las tareas fundamentales en Estadística consiste en determinar, a partir de los resultados observados en una muestra, el modelo que sigue la distribución de una cierta variable en la población estudiada. Una vez determinado, para responder a las cuestiones que interesen bastará con aplicar las propiedades y características del modelo al que se ajusta.
Podemos sospechar que un conjunto de datos obtenidos experimentalmente se ajusta a una distribución binomial cuando se trata de N observaciones, relativas a n individuos de una población estadística, en cada una de las cuales se ha contado el número k de individuos que cumplen una determinada condición. De ese modo, para el análisis partimos de una tabla de frecuencias cuya variable toma los valores 0, 1, 2, ..., n.
Una distribución binomial queda caracterizada por los valores de n y p. En nuestro caso n ya es conocido, ya que viene determinado por los datos de partida. Sin embargo es necesario encontrar el valor de p.
Si la serie de datos experimentales se ajusta
a una distribución binomial, la media,
El ajuste, y las ventajas que supone, carece de valor si no es suficientemente bueno. En todos los casos habrá diferencias entre los datos experimentales y los correspondientes según la ley ajustada, pero habrá que determinar en qué medida esas diferencias están justificadas por el azar, en cuyo caso la ley teórica ajustada es aceptable, o bien son demasiado grandes y debemos suponer que la ley teórica ajustada no es la que realmente siguen los datos experimentales y, por ello, se debe rechazar el ajuste. Para verificar si el ajuste es adecuado:
Vamos a seguir los pasos citados para resolver el siguiente problema:
|
|
Preguntas
|